Intro
환경설정
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=password timescale/timescaledb:latest-pg15create table realtime_datas (
id serial,
event_time timestamptz not null,
data integer not null
);DO $$
DECLARE
_current timestamptz;
random_interval INTERVAL;
random_value INT;
start_date timestamptz := '2024-01-01';
end_date timestamptz := '2024-07-30';
BEGIN
_current := start_date;
WHILE _current <= end_date + INTERVAL '1 day' LOOP
random_interval := (1 + floor(random() * 3))::INT * INTERVAL '1 minute';
random_value := 10 + floor(random() * 11)::INT;
INSERT INTO realtime_datas(event_time, data)
VALUES (_current, random_value);
_current := _current + random_interval;
END LOOP;
END;
$$ LANGUAGE plpgsql;SELECT create_hypertable('realtime_datas', 'event_time', migrate_data=>true);Contents
hyper table을 설정하면, 기본적으로 설정한 column에 대해서 desc 정렬로 index가 자동 생성된다.
_timescaledb_internal에 생성되는 chunk table의 index를 확인해보면, event_time column에 대해서 desc 정렬 index가 자동으로 걸렸다는 것을 확인할 수 있다.

그럼, 만약 이 hyper table에 내가 별도로 index를 걸면 어떻게 되는가?
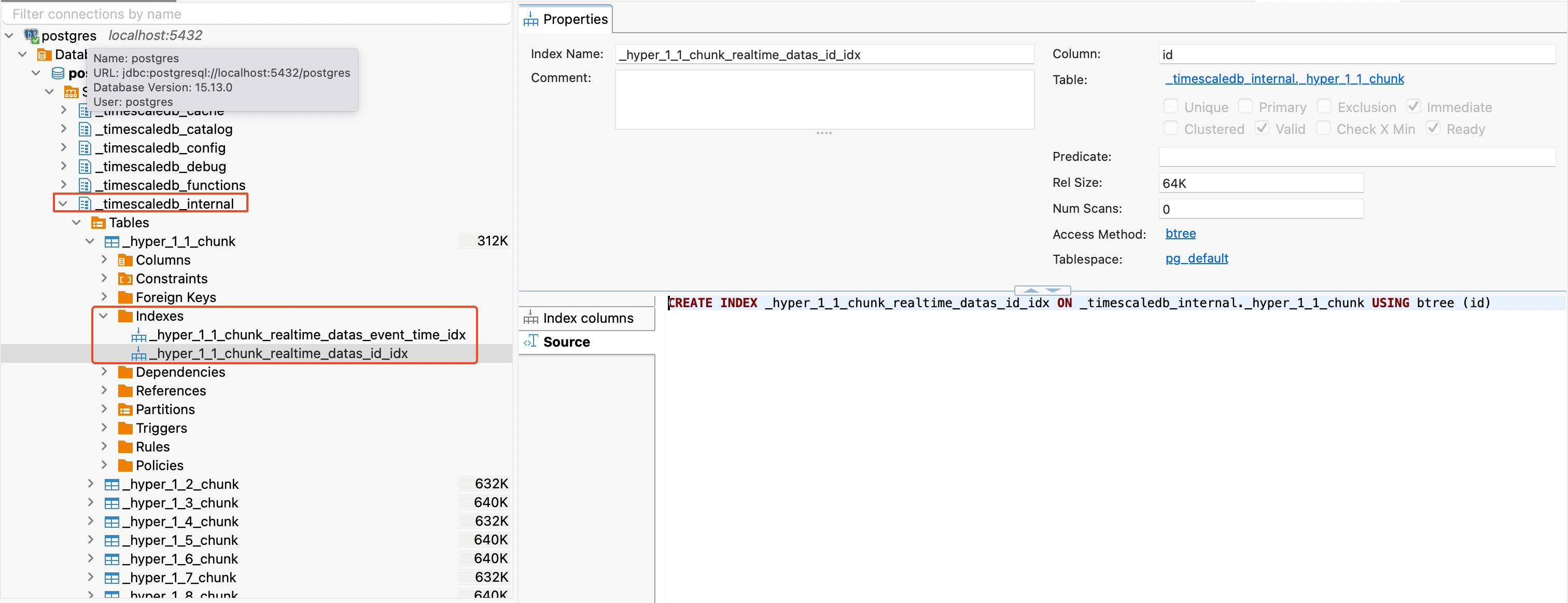
realtime_datas table의 id 부분에 index를 걸어보겠다.
create index on realtime_datas (id);
보이는 바와 같이, 원본 테이블에 indexing이 걸리면서, 모든 chunk table에 동일한 index가 걸리는 것을 확인 할 수 있다.

그래서 timescaleDB의 hyper table은 다음과 같은 조회 순서를 가진다.
1. 어떤 chunk table를 조회해야하는지 선정
2. 해당 chunk들에 postgresql이 어떤 스캔을 할지 선정(index, bitmap, seq)
'IT' 카테고리의 다른 글
| [python] 리스트 잘못 쓰면, 오늘은 정상인데 내일은 망가진다. (0) | 2026.01.07 |
|---|---|
| [개발] AI로 짠 코드, 내가 리뷰하는 건 개발자인가 AI인가 (0) | 2025.12.29 |
| [python] module level __getattr__ (__getattr__ 조금 더 파보기) (0) | 2025.12.20 |
| [백엔드] timestamp를 압축 시켜보자 (0) | 2025.12.18 |
| [백엔드] timestamp의 Z와 +00:00 이야기 (0) | 2025.12.17 |