들어가기 앞서
TimescaleDB는 PostgreSQL 진영의 time series 데이터를 저장하기 위한 DB이다. 시계열 데이터를 처리하기 위해 최적화된 데이터베이스로, 실시간으로 쌓이는 대규모 데이터를 처리하기 위해 만들어졌다.
이 글을 작성하는 이유는, timezone을 계산해야하는 상황에서 쿼리가 보다 빠르게 동작시키기 위해서 고생한 흔적이 들어있다.
내용
환경설정
DB 실행
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=password timescale/timescaledb:latest-pg15
Table 생성
create table realtime_datas (
id serial,
event_time timestamptz not null,
data integer not null
);
더미데이터 생성
DO $$
DECLARE
_current timestamptz;
random_interval INTERVAL;
random_value INT;
start_date timestamptz := '2024-01-01';
end_date timestamptz := '2024-07-30';
BEGIN
_current := start_date;
WHILE _current <= end_date + INTERVAL '1 day' LOOP
random_interval := (1 + floor(random() * 3))::INT * INTERVAL '1 minute';
random_value := 10 + floor(random() * 11)::INT;
INSERT INTO realtime_datas(event_time, data)
VALUES (_current, random_value);
_current := _current + random_interval;
END LOOP;
END;
$$ LANGUAGE plpgsql;- 위 동작으로 약 15만개의 데이터가 생성된다.
하이퍼 테이블 생성은 아래 분석 도중에 진행한다.
분석
기본적인 TimescaleDB에 대한 동작 방식은 https://nebulayoon.tistory.com/11 여기서 확인 할 수 있다.
요구사항: 각 나라에서 우리 서비스를 사용하게 되는데, 해당 유저가 특정 날짜의 데이터를 요구한다.
가정
- 우리는 모든 유저의 데이터를 UTC로 realtime_datas table에 저장하고 있다고 가정한다.
- 유저의 위치에 따라서 날짜가 적용된다고 가정한다.
위의 요구사항을 보면, 유저에 따라서 특정 날짜의 데이터가 다르다는 것을 알 수 있다. 우리나라는 UTC+9으로 UTC에 9시간을 더한 시간을 사용하지만, 미국 캘리포니아 주는 UTC-7을 사용한다.
즉, 유저가 '2024-06-01'의 데이터를 요구한다면, UTC '2024-06-01'이 아니라, 유저가 한국에 있다면 'Asia/Seoul'을 기준으로 '2024-06-01 00:00:00' ~ '2024-06-01 23:59:59'의 데이터를 보여줘야한다.
UTC로 다시 생각해보자면 realtime_datas table에서, UTC '2024-05-31 15:00:00' ~ '2024-06-01 14:59:59'를 검색해야한다.
우선, 바로 select 해본다.
select
*
from realtime_datas
where
date(event_time at time zone 'Asia/Seoul') = '2024-06-11'
데이터가 15만개 밖에 되지 않고, select query가 간단하다 보니 빠르게 select된다.
하지만, 해당 쿼리를 평가해보면, 문제가 있다는 것을 알 수 있다.
바로 sequential scan을 진행한다는 것이다.

sequential scan은 모든 데이터를 검색하는 만큼, 모든 row에 대해서 진행되었다는 것을 알 수 있다.
한국 날짜를 기준으로 '2024-06-11' 날짜의 데이터를 찾기 위해서 DB가 연산을 했다는 것을 알 수 있다.
이는 곧, 데이터가 늘어나면 늘어날 수록 느려지는 query이다.
하지만, 내가 원하는 것은 모든 데이터를 검색하는 것이 아닌, 범위를 줄여서 더 빠르게 동작하도록 만드는 것이다.
이번에는 TimescaleDB의 hypertable을 이용해서, 제대로 DB를 사용해보겠다.
SELECT create_hypertable('realtime_datas', 'event_time', migrate_data=>true);
위 쿼리로 realtime_datas table에 hypertable을 적용시키고, 똑같은 쿼리를 사용한다.
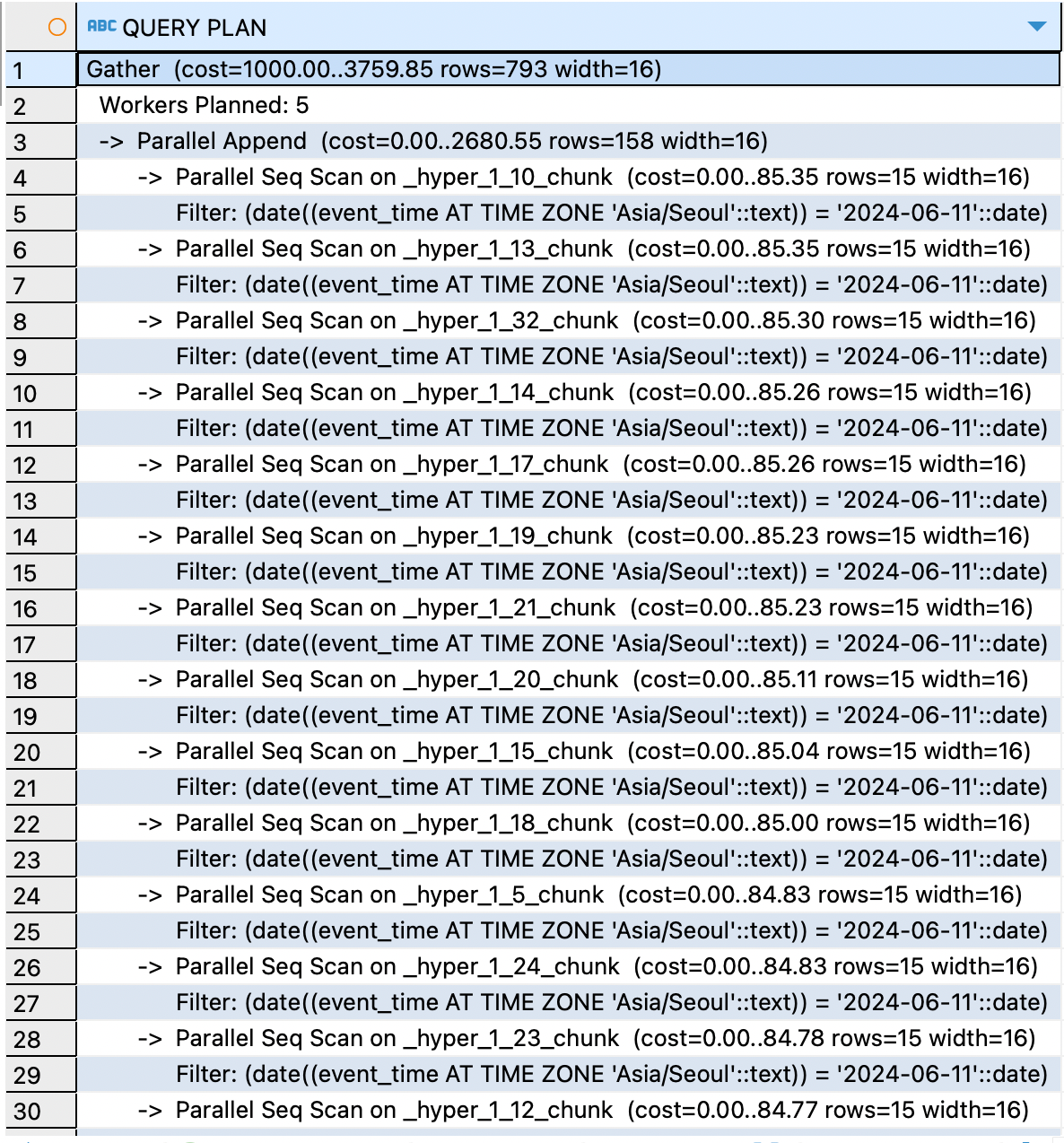
위 와 같이, scan 방식이 바뀌었다. TimescaleDB는 chunk를 기준으로 스캔한다는 것을 알 수 있는데, 많은 chunk를 scan한다는 것을 알 수 있다.
제일 위의 1_10_chunk데이터를 확인해보겠다.
SELECT
min(event_time at time zone 'Asia/Seoul'),
max(event_time at time zone 'Asia/Seoul')
FROM "_timescaledb_internal"."_hyper_1_10_chunk";

전혀 상관 없는 날짜의 데이터도 스캔한다는 것을 알 수 있다. 결국, 나눠서 연산을 진행하지만, time zone 'Asia/Seoul'로 인해서, 결국 모든 데이터를 확인하는 것이다.
아이디어
TimescaleDB는 date와 관련된 쿼리는 chunk를 이용하며, 어떤 chunk를 사용해야하는지 where 절을 보고 결정한다.
어? 그러면, timezone을 연산하기 전에, where절로 데이터를 미리 자르면 어떻게 동작하지?
위 아이디어를 이용해서, 다음과 같이 쿼리를 작성해보겠다.
select
*
from realtime_datas
where
event_time >= date('2024-06-11') - interval '1 day'
and event_time <= date('2024-06-11') + interval '1 day'
and date(event_time at time zone 'Asia/Seoul') = '2024-06-11'
at time zone 'Asia/Seoul'을 이용해서 한국 날짜로 '2024-06-11'의 데이터를 가져오는 것임은 똑같다. 그러나 where절에 UTC를 기준으로 대략 '2024-06-10' ~ '2024-06-12'의 데이터를 가져오겠다고 명시한다.
위에서 1 day로 명시한 이유는 UTC시간을 기준으로 모든 나라의 timezone 데이터를 표현하기에 충분하기 때문이다.
UTC보다 최대 14시간 빠른(예: 키리바시의 라인 제도)가 존재하기 때문에, 모든 timezone에서 데이터 lose가 없도록 하려면, 1 day 안에서 해결해야 한다.
(가장 느린시간은 UTC-12이다)

plan이 확 줄었다. 1_27_chunk를 확인하고 있으니, 해당 chunk의 데이터를 확인해보면,

제대로 관련된 날짜의 데이터만 있는 chunk에서 time zone을 연산하고, 데이터를 가져오는 것을 알 수 있다.
'IT' 카테고리의 다른 글
| [python] shallow copy, deep copy, pass by assignment (0) | 2024.08.31 |
|---|---|
| [python] vscode dotenv.load_dotenv() os.getenv()가 최신화 되지 않는 문제 (0) | 2024.08.25 |
| [TimescaleDB documents] time_bucket() (0) | 2024.08.18 |
| [fastapi documents] OpenAPI operationId (0) | 2024.08.17 |
| [python documents] python3.11 pep655 TypeDict (0) | 2024.08.11 |

