Contents
최근에 황당한 일을 겪게 되어 정리해본다.
동일한 시나리오를 한번 작성해 보겠다.
우선 아래와 같이 테스트 환경을 구축한다.
환경설정
- python3.11
- pandas
- psycopg3
- postgresql 15
- dockerfile
FROM postgres:15
EXPOSE 5432- docker-compose.yml
version: '3.8'
services:
db:
build: .
container_name: pg15-local
restart: unless-stopped
ports:
- "5432:5432"
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: postgres
volumes:
- ./pgdata:/var/lib/postgresql/data
volumes:
pgdata:
본론에 들어가기 앞서서 질문을 해보겠다.
다음 DDL을 보고, value column에 들어갈 수 있는 값들은 무엇인가?
create table test_table (
value numeric(9, 2) not null,
created_at timestamptz not null default now()
)
생각해 보았는가?
numeic type으로 되어 있는 대다가 not null이기 때문에, "소수점을 표현할 수 있는 숫자 타입" 만 들어갈 수 있다고 생각했다면, 틀렸다.
NaN, Infinity, -Infinity 문자열 값이 들어갈 수 있다.
공식문서에 따르면, IEEE 754 표준에 의거해서, NaN, Infinity, -Infinity 문자열을 넣을 수 있다고 한다.
https://www.postgresql.org/docs/15/datatype-numeric.html
실제로 그런지 확인해보겠다.
코드는 어렵지 않다.
csv 파일을 읽어서, 그 데이터를 PostgreSQL DB에 insert할 뿐이다.
import pandas as pd
import psycopg
df = pd.read_csv('test.csv', parse_dates=['created_at'])
conn_url = "postgresql://postgres:postgres@localhost:5432/postgres"
with psycopg.connect(conn_url) as conn:
with conn.cursor() as cur:
records = list(df.itertuples(index=False, name=None))
cur.executemany(
"INSERT INTO test_table (value, created_at) VALUES (%s, %s)",
records
)
print("Done")value,created_at
1,2025-07-17T23:51:03
2,2025-07-17T23:52:04
3,2025-07-17T23:53:05
,2025-07-17T23:54:06
5,2025-07-17T23:55:07
6,2025-07-17T23:56:08
7,2025-07-17T23:57:09
8,2025-07-17T23:58:10
9,2025-07-17T23:59:11
10,2025-07-17T23:59:59
그런데 여기서 주목해야하는 점은 value가 3인 row와 5인 row 사이에서 빈 값이 존재한다는 것이다.
pandas를 통해서 csv파일을 읽었으므로, Dataframe을 출력시켜보면 다음과 같이 나온다.

Pandas는 빈 값을 NaN으로 표시한다. 엥, 그러면 설마 DB에 NaN이 들어가나?
놀랍게도, "숫자" 타입만 들어가기를 원하는 개발자의 바람과는 다르게, 'NaN' 이 들어간다.

공식 문서에서 보면 UPDATE table SET x = '-Infinity'를 사용하면, '-Infinity'와 같은 값을 넣을 수 있다고 하니 하는 김에 도전해본다.
test_table에서는 numeric(9, 2) 와 같이, 필드의 크기를 정해줬기 때문에 infinite value를 넣을 수 없다고 한다.

test2_table을 만들고 값을 채워보겠다. 이번에는 크기 지정 없이, 그냥 numeric type으로 지정한다.
create table test2_table (
value numeric not null,
created_at timestamptz not null default now()
)
UPDATE test2_table SET value = '-Infinity'
정말로, -Infinity 라는 문자열이 들어갔다.
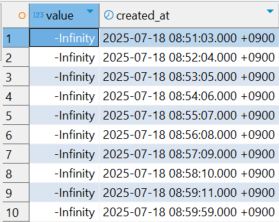
나의 실수
별거 아닌 것 같지만(아니 별거 맞다), 큰 이슈가 발생했다.
csv파일에 항상 값이 있어야 한다는 룰이 존재했음에도,
하필, value의 값이 비어있는 csv파일이 백엔드에 전달되었고,
하필, pandas는 빈 값을 NaN으로 표시하고,
하필, value 필드는 numeric type이였고,
하필, postgresql은 numeric type일 경우, NaN 문자열을 허가 했고,
하필, 백엔드 서버는 해당 값을 다시 DB에 호출했고,
하필, JSON은 RFC 8259 표준에 의거하여, NaN json 직렬화를 실패했다.
하필, json 직렬화를 실패한 백엔드 서버는 500번대 에러를 발생한다.
모든 코드에서 설마 NaN이 들어갈 것이라고는 상상도 못했고, 이로 인해서 모든 시스템이 도미노 처럼 쓰러질 것이라고는 상상도 못했다.
이 글을 기준으로 두번 다시 이런 실수는 하지 않겠다.
References
'IT' 카테고리의 다른 글
| [LLM] 모든 모델을 쓰고 싶은 라이트 유저들의 플랫폼(T3 chat) (0) | 2025.09.07 |
|---|---|
| [Python] .get을 써야 하는 가? 인덱싱(subscription)을 써야 하는 가? (0) | 2025.07.30 |
| [python] pydantic 2.0 decimal.Decimal type to float (with. postgresql) (0) | 2025.07.16 |
| [FastAPI] fastapi와 DB간의 session 로깅하기 (0) | 2025.07.06 |
| [ChatGTP] AI로 조금 더 효율적이게 공부하는 방법 (0) | 2025.07.05 |


